<今回やること!>
Excelで、セルに数字の0を入力したら×、1を入力したら○が表示されるように設定します。↓こんな感じです。
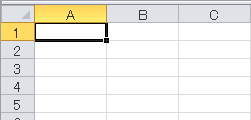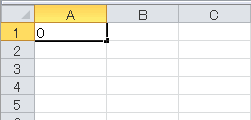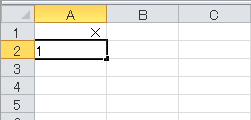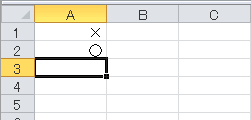
マクロではなく、セルの書式設定を使用します。
『○/×』以外にも『OK/NG』や『優/良/可』等、三択までなら同様に設定可能です。逆に言うと、三択までしか出来ません。これはExcelの仕様のためです。
以降で、詳しいやり方を説明します。 続きを読む

mmorley.hatenablog.com
↑の記事のプログラムの派生版です。
文字の検索(match())や文字の置換(replace()関数)を使って、ファイル名を変更します。
フォルダ内の複数のファイルからmatch()を使って対象のファイルを絞り込み、replace()で新しいファイル名を作成します。
変更前には、変更内容を確認します。
ユーザーに確認を取るための対話型処理については、冒頭の記事で説明しています。
Node.jsのデバッグ環境が欲しい!ということで調べると、Visual Studio Code(以下、VSCode)で簡単に出来ることがわかりました。
VSCodeは既にエディタとして利用しているので、早速試してみました。
↓こちらの記事で、Node.jsの環境を作成しました。
mmorley.hatenablog.com
Node.jsの使用例を見ていたら、ファイル操作が出来ることを発見!ここでのファイル操作とは、ファイルの名前変更、削除、ファイル情報の取得等です。
ブラウザ上で動く従来のJavaScriptでは出来なかったので盲点でした。個人的には、不慣れなunixコマンドよりいろいろ出来そうです。
ファイル操作に関する関数群は、Node.jsの標準モジュールに含まれています。Node.jsには使いたいライブラリをnpmで組み込んで使用する仕組みがありますが、標準モジュールは最初から組み込まれています。
標準モジュールに含まれる関数群の詳細は、公式のAPIリファレンスで確認出来ます。
ということで、今回は試しにファイル内のフォルダを列挙するプログラムを作成します。
またNode.jsのプログラムでは、同期処理、非同期処理に注意する必要があります。今回は試しにそれぞれ作ってみます。
<前置き>
画像から文字を読み込むOCRについて調べていたら、Tessract.js(テッサラクト・ジェイエス)というライブラリを発見しました。
なんと純粋なJavaScriptで書かれているとのこと。しかも60以上の言語を認識出来るらしいです。
さっそく手順に従ってHTMLに組み込んでみましたが、ブラウザがローカルデータへのアクセスを制限されているため失敗しました。
ブラウザにアクセス許可を与えるのは怖いなと思ったのですが、他に『Tesseract.jsをnpmでインストールして、requireして使う方法』が書いてありました。出てきた用語だいたいわかりません。
npm?、require?、どういうこと?と思って調べると、まずはNode.jsを導入する必要があることがわかりました。
Node.jsは、従来のHTMLに組み込むJavaScriptとは別物でしたが、調べるとBrowserifyという従来のJavaScriptと結びつける方法もあるようなので、中々おもしろそうです。
ということで、名前は知っていたものの横目で見るだけだったNode.jsをこれを機に導入することにしました。
<ここから本題>
調べたところNode.jsを直接インストールするより、Homebrew→Nodebrew→Node.jsの順にインストールするのが後々を良いようです。
その理由となるそれぞれの役割について、簡単にですがまとめました。
また、YosemiteやEl Capitanで、Homebrew経由でインストールするとNodebrewがうまく動かないという記事がありましたが、私の環境(El Capitan)では問題は起きていません。
実際にインストールした手順をまとめました。
インストール後に、Node.jsで実際に、HelloWorldプログラムとTessract.jsを使った文字認識を実行しました。