
【 今回やること! 】
- 『Anaconda(アナコンダ)』をインストールします。
- 『Anaconda』でPythonの開発環境を構築します。
- プログラムの作成と実行が出来る『Jupyter Notebook』をインストールします。
- 『Jupyter Notebook』でPythonのプログラムを実行します。
- 下記の記事で『Google Colaboratory』で動かしたプログラムを少し修正して実行します。
mmorley.hatenablog.com
- 下記の記事で『Google Colaboratory』で動かしたプログラムを少し修正して実行します。
『Anaconda』はPythonの開発環境を簡単に構築するためのパッケージです。
ここでいう開発環境とは、Python本体・ライブラリ・コードエディタ・実行環境のセットです。それぞれバージョンや種類を自由に組み合わせて環境を構築することが出来ます。
Pythonのエディタとして有名な『Jupyter Notebook(ジュピター ノートブック)』も、『Anaconda』のパッケージに含まれています。『Jupyter Notebook』はドキュメント・コード・実行結果をまとめて編集出来るエディタです。『Google Colaboratory』は『Jupyter Notebook』を元に作られているそうです。
これまで『Google Colaboratory』をメインで使っていましたが、やはり環境がリセットされてしまうのがネックです。また元から入っているライブラリは、Googleが知らぬ間にバージョンを変更する可能性があります。なので自分で管理出来るローカル環境を作成したいと思いました。
『Anaconda』を使ってPythonのローカル環境を作成し、プログラムを実行するまでの手順を説明します。
目次
『Anaconda』の公式サイト
- 公式サイト
www.anaconda.com
『Anaconda』のインストール
- 下記のサイトを開きます。
Anaconda | Individual Edition
- 『Windows』の『64-Bit Graphical Installer (462 MB)』をクリックします。
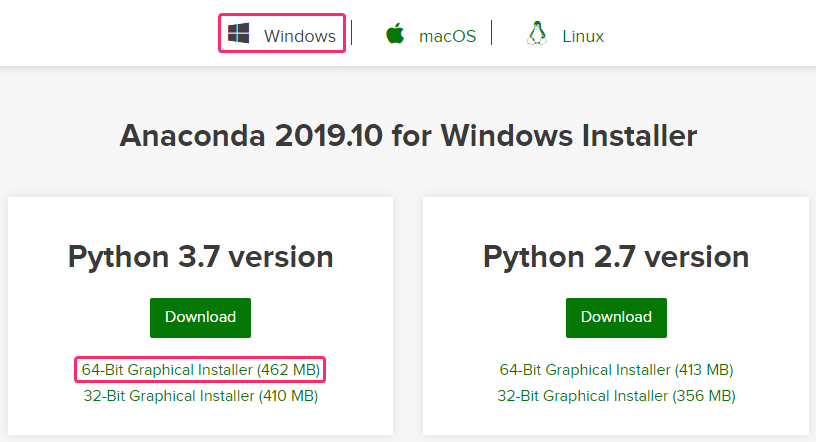
『Anaconda3-2019.10-Windows-x86_64.exe』がダウンロードされます。
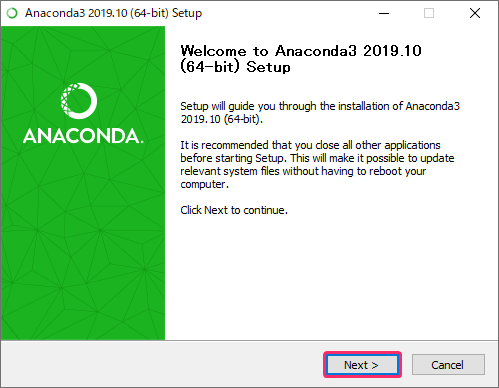
- 『Anaconda3-2019.10-Windows-x86_64.exe』をダブルクリックして実行します。
- 『Next』をクリックします。
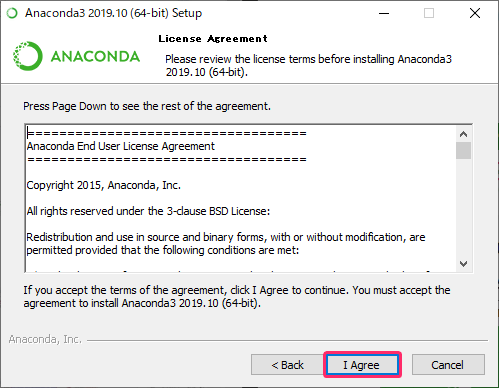
- 『I Agree』をクリックします。
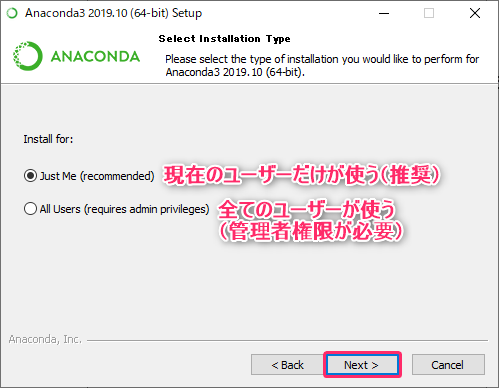
- ”使用するユーザー”を選択して、『Next』をクリックします。
この手順では『Just Me(recommended)』を選択します。
- ”インストール先のフォルダ”を選択して、『Next』をクリックします。
- ”高度インストールオプション”を選択して、『Install』をクリックします。
この手順ではデフォルトのままにしています。
【 和訳 】
- AnacondaをPATH環境変数に追加する
おすすめしません。 代わりに、Windowsの[スタート]メニューでAnacondaを開き、[Anaconda(64-bit)]を選択します。 この「PATHに追加」オプションを使用すると、以前にインストールしたソフトウェアの前にAnacondaが検出されますが、Anacondaをアンインストールして再インストールする必要があるという問題が発生する可能性があります。
チェックを入れると、Anaconda以外のPython環境を使う場合に不具合が起きる可能性があるらしいです。
- AnacondaをデフォルトのPython 3.7として登録する
これにより、Visual Studio PyCharm、Wing IDE、PyDev、MSIバイナリパッケージ用のPythonツールなどの他のプログラムが、システム上のプライマリPython 3.7としてAnacondaを自動的に検出できるようになります。
- AnacondaをPATH環境変数に追加する
- インストールが開始されるので、完了まで待ちます。
- 『Next』をクリックします。
- 『Next』をクリックします。
【 和訳 】
AnacondaとJetBrainsは連携して、PyCharm IDEに緊密に統合されたAnaconda搭載の環境を提供します。
これは宣伝ですかね。
- 『Finish』をクリックします。
チェックを付けるとそれぞれ下記のページが開きます。

【 和訳 】
Anacondaは、最も人気のあるPythonデータサイエンスプラットフォームです。
Anaconda Cloudでノートブック、パッケージ、プロジェクト、環境を共有しましょう!- Anaconda Cloudの詳細について学習する。チェックを入れると下記のページが開きます。
https://anaconda.org/
- Anacondaの始め方について学習する。チェックを入れると下記のページが開きます。
docs.anaconda.com
- Anaconda Cloudの詳細について学習する。チェックを入れると下記のページが開きます。
『Anaconda Navigator』でPythonの開発環境を構築する
- 『Windows』の『スタートメニュー』を開き、『Anaconda3 (64-bit)』-『Anaconda Navigator (Anaconda3)』をクリックします。
- 下図の画面が出るので、お好みでチェックをオンオフして、『Ok, and don't show again(OK、再度表示しない)』をクリックします。
【 和訳 】
Anaconda Navigatorは、重要なPythonアプリケーションを簡単に起動し、ローカルのAnacondaインストールのパッケージを管理するのに役立ちます。また、Python、SciPy、およびPyDataコミュニティを学習し、活用するためのオンラインリソースに接続します。
Anaconda Navigatorの改善、バグの修正、Pythonを誰でも簡単に使用できるようにするために、ほとんどのWebブラウザーやモバイルアプリと同様に、匿名化された使用情報を収集します。
これをオプトアウト(拒否)するには、以下のチェックを外してください(この設定は[設定]メニューでいつでも変更できます)。- はい、Anacondaの改善に協力したいと思います。
ここから『Anaconda Navigator』で作業
- 『Environments』をクリックして、次に『Create』をクリックします。

- 下図のように設定して『Create』をクリックします。
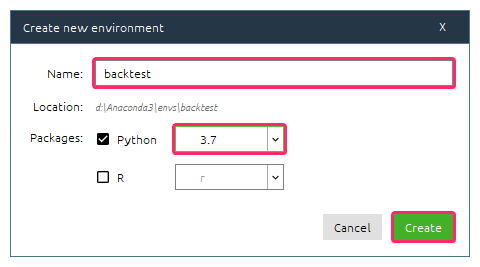
Pythonの開発環境として『backtest』が作成されます。
- 『Home』をクリックして『backtest』を選択し、『Jupyter Notebook』の『Install』をクリックします。

- 『Launch』をクリックします。
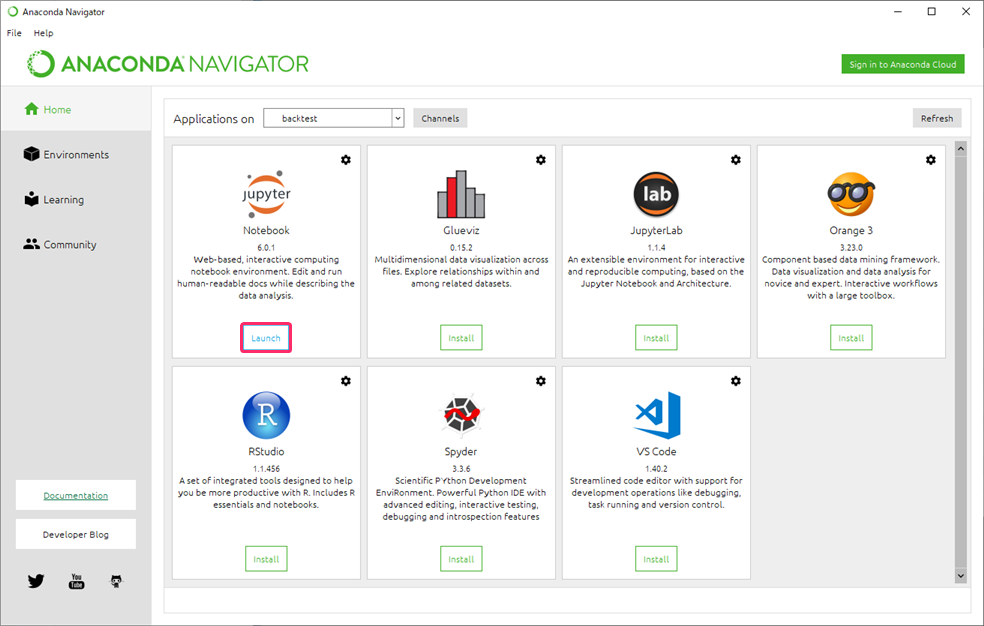
ブラウザが起動して『Jupyter Notebook』のページが開きます。
『Jupyter Notebook』でプログラムを実行する
作業フォルダを作る
- フォルダ一覧の『Desktop』をクリックして、次に『New』→『Folder』をクリックします。

- 『Untitled Folder』のチェックをONにして、『Rename』をクリックします。

- 好きな名前を付けて、『Rename』をクリックします。
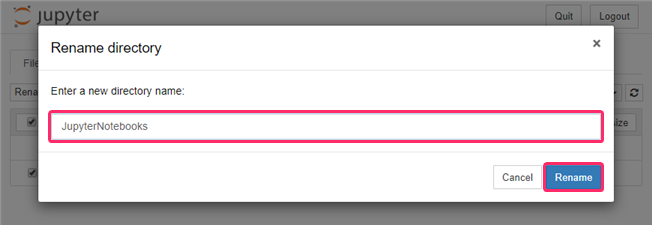
ここでは『JupyterNotebooks』と付けています。
ここから『Jupyter Notebook』で作業
新規『Notebook』を作る
『Notebook』はドキュメント・コード・実行結果をまとめて保存できるファイルです。
- 『JupyterNotebooks』フォルダをクリックして開いて、次に『New』→『Python 3』をクリックします。

『新規Notebook』のページが開きます。
- Notebookの名前の『Untilted』をクリックします。

- 好きな名前を付けて、『Rename』をクリックします。
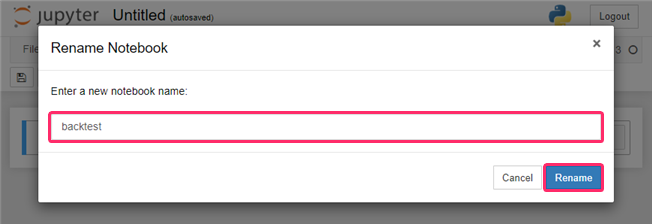
ここでは『backtest』と付けています。
コードを貼り付ける
- 『コードセル』に下記のコードを貼り付けます。
これは『FXDD』というサイトから、FXのヒストリカルデータをダウンロードしてCSVファイルに変換するコードです。詳しい内容は下記の記事で説明しています。%%time # ↑セルの処理時間を計算 %%timeはセルの最初に単独で書く import os # ディレクトリ作成、パス結合、ファイル削除 import datetime # 日付取得 import requests # ダウンロード処理 import zipfile # zip解凍 import numpy as np # 数値データ高速処理 import pandas as pd # データ構造化 # 取得・作成したデータを保存するディレクトリのパス hst_dir = os.path.join(os.getcwd(), 'hst_' + datetime.datetime.today().strftime('%Y%m%d')) if not os.path.exists(hst_dir): # ディレクトリが無い場合 os.mkdir(hst_dir) # ディレクトリを作成 # 取得する通貨ペアを指定 list = ['USDJPY'] for item in list: print(item) zip_url = 'http://tools.fxdd.com/tools/M1Data/' + item + '.zip' # ダウンロード元url zip_file = os.path.join(hst_dir, item + '.zip') # 保存先ファイル名 req = requests.get(zip_url) with open(zip_file, 'wb') as f: f.write(req.content) print(' :ダウンロード完了') # zipファイルを解凍する with zipfile.ZipFile(zip_file, 'r') as f: # 読み込みモードで開く f.extractall(hst_dir) # zip展開 print(' :zip解凍完了') # hstファイルをcsvファイルに保存する with open(os.path.join(hst_dir, item + '.hst'), 'rb') as f: # hstのヘッダ(148byte)からバージョン(先頭の4byte)を取得 # dtype='i4':符号あり32ビット整数型 ver = np.frombuffer(buffer=f.read(148)[:4], dtype='i4') if ver == 400: # バージョンが400の場合 # 1行のデータの並びを定義 dtype = [ ('DateTime', 'u4'), # 'u4':符号なし32ビット整数型 ('Open', 'f8'), # 'f8':符号あり64ビット整数型 ('Low', 'f8'), # ('High', 'f8'), # ('Close', 'f8'), # ('Volume', 'f8') # ] elif ver == 401: # バージョンが401の場合 # 1行のデータの並びを定義 dtype = [ ('DateTime', 'u8'), # 'u8':符号なし32ビット整数型 ('Open', 'f8'), # 'f8':符号あり64ビット整数型 ('Low', 'f8'), # ('High', 'f8'), # ('Close', 'f8'), # ('Volume', 'f8') # ('Spread', 'i4'), # 'i4':符号あり32ビット整数型 ('RealVolume', 'i8') # ] # バイナリデータをPandasのデータフレームに変換する df = pd.DataFrame(np.frombuffer(buffer=f.read(), dtype=dtype)) # DateTime列を日付データに変換してインデックスに設定して、変換前の列を削除する df = df.set_index(pd.to_datetime(df['DateTime'], unit='s')).drop('DateTime', axis=1) display(df.head(2)) # データの先頭2行を書き出す display(df.tail(2)) # データの末尾2行を書き出す #csvファイルに保存 df.to_csv(os.path.join(hst_dir, item + '.csv')) print(' :csvに変換完了') # ファイルを削除 os.remove(zip_file) # zipファイル削除 os.remove(os.path.join(hst_dir, item + '.hst')) # hstファイル削除 print(' :zip、hst削除完了')
必要なライブラリを追加する
- 必要なライブラリが足りないのですが、試しに『Run』をクリックして実行します。
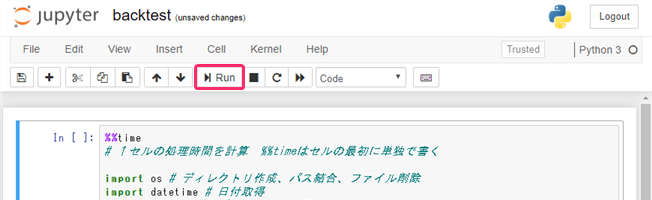
- 実行した『コードセル』の下に"必要なライブラリ名"がエラー表示されるので、その下の『コードセル』に下図のように入力して、『Run』をクリックします。

!pip install requests
『requests』ライブラリがインストールされます。
- 『コードセル』で下図のコマンドを実行し、他に必要なライブラリをインストールします。
先程と同様にエラーメッセージで必要なライブラリ名を確認しています。

!pip install numpy !pip install pandas
- 再び最初の『コードセル』を実行します。
下図のように結果が表示され、デスクトップの『JupyterNotebooks/hst_(日付)』フォルダ内に『USDJPY.csv』が保存されます。
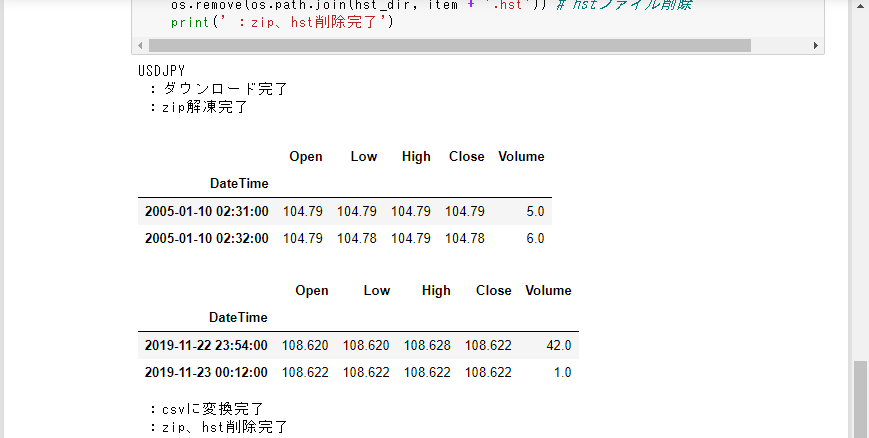
補足
『Jupyter Notebook』の起動フォルダを変更する
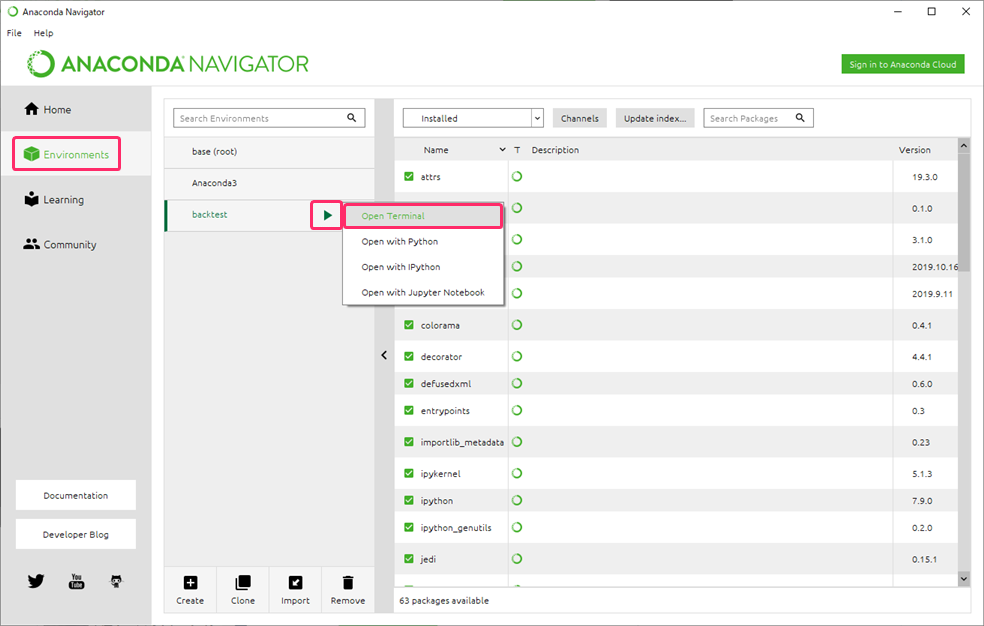
- 『Environments』をクリックして、『backtest』の『▶』→『Open Terminal』をクリックします。
- 『コマンド プロンプト』が起動するので、下記のコマンドを貼り付けて実行します。
jupyter notebook --generate-config
- 『jupyter_notebook_config.py』が作成されて、その場所が表示されます。
Writing default config to: C:\Users\(ユーザー名)\.jupyter\jupyter_notebook_config.py
ここから『Windows アクセサリ』の『メモ帳』で作業
- 『エクスプローラー』で『jupyter_notebook_config.py』を含むフォルダを開き、『jupyter_notebook_config.py』をメモ帳にドラッグ&ドロップします。
- メモ帳で『Ctrl + f』キーを押して、『c.NotebookApp.notebook_dir』を検索します。
- 下図の部分を変更して上書き保存します。
- 変更前
## The directory to use for notebooks and kernels. #c.NotebookApp.notebook_dir = ''
- 変更後
## The directory to use for notebooks and kernels. c.NotebookApp.notebook_dir = 'C:\Users\(ユーザー名)\Desktop\JupyterNotebooks'
- 先頭の”#(シャープ)”を削除します。
- 好きなフォルダを設定します。
- 先頭の”#(シャープ)”を削除します。
- 『Jupyter Notebook』を再起動して、起動フォルダが変更されていることを確認します。
- 変更前
ここから『Anaconda Navigator』で作業
『コードセル』の幅をブラウザの幅に合わせる
ブラウザの幅を変更したときに、『コードセル』の幅も合わせて変更されるようにします。
『Notebook』ごとに一度実行する必要があります。
- 『コードセル』に下記のコードを貼り付けて、『Run』をクリックします。
%%HTML <style> div#notebook-container { width: 95%; } div#menubar-container { width: 65%; } div#maintoolbar-container { width: 99%; } </style>
ここから『Jupyter Notebook』で作業
あとがき
『Jupyter Notebook』以外にもエディタがありますが、『JupyterLab』を使ったときにグラフが上手く表示されないケースがあったので『Jupyter Notebook』を使っています。